
Ollama
Ollama is an open source tool to install, run & manage different LLMs on our local machines like LLama3, Mistral and many more.
Install Ollama from here: https://ollama.com/download
After the installation, you should be able to use ollama cli. Start by pulling the llama3 model first.
ollama pull llama3
It’s 4.7GB so it might take a while to install depending on your internet speed, wait until it completes. After the installation, you can run it in your terminal with ollama run llama3 and play around but I’ll just serve it in an unused port on my local machine. Default port is 11434. See the API details from here: https://github.com/ollama/ollama/blob/main/docs/api.md
OLLAMA_HOST=127.0.0.1:11435 ollama serve
Project Setup
LangChain
LangChain is a very popular framework to create LLM powered applications with abstractions over LLM interfaces. It has Prompt Templates, Text Splitters, Output Parsers, Document Loaders and many more built-in features that helps us in development lifecycle.
Vector Store and Vector Search
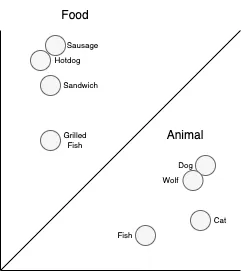
Vector search has been part of our lives for a long time. Traditional keyword searches often fall short because computers don’t inherently understand the words we speak. They struggle to search by meaning rather than just spelling. For instance, if you’re searching for “hotdog” you expect to find results related to food. However, keyword searches might miss relevant results due to variations in language and spelling.
Instead of doing a keyword search, embeddings are created for each word (images, videos, and other things can also be embedded). These embeddings are numerical representations that capture the essence of the content. When you search for “hotdog,” the search algorithm looks for embeddings that are close to the embedding of “hotdog” in the vector space. This allows the system to understand the semantic meaning behind the search query and return results that are contextually relevant, such as pictures of hotdog, sausage, sandwich etc. instead of dogs and puppies.
Application
I’ll develop a Q & A bot that uses given dataset as the source using RAG (Retrieval-Augmented Generation). For this small application I’ll use the Elon Musk’s latest speech from one of his gaming streams where he speaks about Starship, Tesla, Optimus and X.
First, create an empty NodeJS project with npm init -y and then install the necessary dependencies.
npm i langchain @langchain/community dotenv @supabase/supabase-js
Supabase
Go to Supabase Dashboard and create your project. I am not gonna detail it but it’s pretty easy. After the creation go to your SQL Editor and create your tables and stuff. See here for resource.
-- Enable the pgvector extension to work with embedding vectors
create extension vector;
-- Create a table to store your documents
create table documents (
id bigserial primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector(4096) -- 4096 works for Ollama embeddings, use 1536 for OpenAI
);
-- Create a function to search for documents
create function match_documents (
query_embedding vector(4096),
match_count int DEFAULT null,
filter jsonb DEFAULT '{}'
) returns table (
id bigint,
content text,
metadata jsonb,
embedding jsonb,
similarity float
)
language plpgsql
as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
(embedding::text)::jsonb as embedding,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where metadata @> filter
order by documents.embedding <=> query_embedding
limit match_count;
end;
$$;
Table creation is clear but maybe our match function might be bit complicated. Essentially it takes 3 arguments, first is the query_embedding (our embedded question), second is the match_count number of records to be returned (ordered by most similar) and the third is filter for metadata.
filter is out of context for our use case but essentially it filters the search output by the metadata. For example you might have PDF file embedded and have the page numbers in metadata that can be filtered.
Coding
Start by initializing the LLM, Embeddings and Vector Store.
import 'dotenv/config'
import { Ollama } from '@langchain/community/llms/ollama';
import { SupabaseVectorStore } from "@langchain/community/vectorstores/supabase";
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";
import { createClient } from "@supabase/supabase-js";
const ollamaBaseUrl = "http://localhost:11435";
const ollamaModel = "llama3";
const llm = new Ollama({
baseUrl: ollamaBaseUrl,
model: ollamaModel,
});
const supabaseClient = createClient(process.env.SUPABASE_URL, process.env.SUPABASE_KEY);
const embeddings = new OllamaEmbeddings({
baseUrl: ollamaBaseUrl,
model: ollamaModel,
});
const vectorStore = new SupabaseVectorStore(embeddings, {
client: supabaseClient,
tableName: "documents",
queryName: "match_documents",
});
// if you don't want to use Supabase
/*
import { MemoryVectorStore } from 'langchain/vectorstores/memory';
const vectorStore = new MemoryVectorStore(embeddings);
*/
OllamaEmbeddings is an object used for texts/documents to be embedded when adding to the database. Essentially it takes our unstructured data and structures it before saving by calling the Ollama API. See OpenAIEmbeddings for OpenAI.
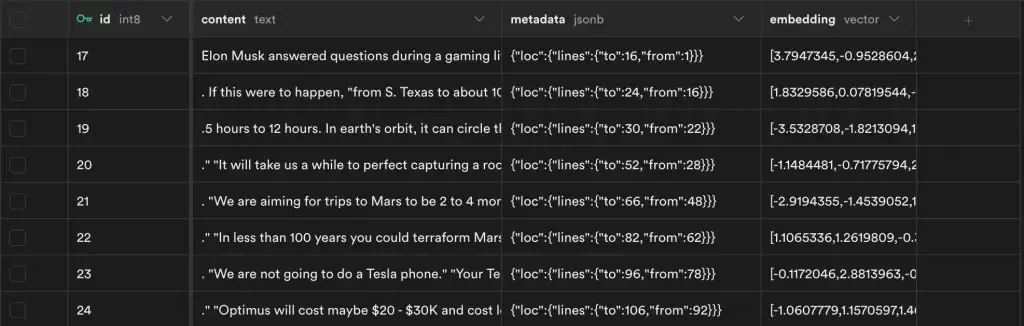
Main part of the implementation:
import { createStuffDocumentsChain } from "langchain/chains/combine_documents";
import { pull } from "langchain/hub";
import { StringOutputParser } from "@langchain/core/output_parsers";
import { Ollama } from '@langchain/community/llms/ollama';
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { readFileSync } from 'node:fs'
// llm, vectorStore in the scope
!async function () {
// read the file and then split it into chunks & then create documents of it
const file = readFileSync('./elon.txt', 'utf-8');
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
separators: ['.', '?', '!', '\n\n']
});
const docs = await splitter.createDocuments([file]);
// add documents to the vector store (that's where embeddings are created)
await vectorStore.addDocuments(docs);
// get the retriever object from the vector store
const retriever = vectorStore.asRetriever();
const question = "Optimus's price?";
// first do a similarity search on the documents in vector store
const retrievedDocs = await retriever.invoke(question);
// pull the rag prompt from langsmith
const prompt = await pull("rlm/rag-prompt");
// initiate the rag chain with our LLM, prompt and outputparser
// to convert the model output to standardized string
const ragChain = await createStuffDocumentsChain({
llm,
prompt,
outputParser: new StringOutputParser(),
});
// pass the question and the relevant docs to the LLM
const result = await ragChain.invoke({ question, context: retrievedDocs });
console.log(result); // Optimus will cost around $20-$30K, which is less than a car.
}()


What’s happening essentially is that we first do a similarity search on documents in the database. Then passing those documents to the LLM using RAG Chain with the prompt and get the response. You can create your own prompts with LangChain to provide more info to the LLM, see rag-prompt we used:
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don’t know the answer, just say that you don’t know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
That’s it, a straightforward Q & A bot that answers the questions based on the given dataset.
Many thanks to our teammate Doğukan Akkaya for providing this awesome blog – be sure to follow Doğukan at https://medium.com/@dogukanakkaya for all his latest posts.
Related Articles

The Agentic Approach to Product Building: Do More with Less
Stop building "clicky" products and start building "asky" ones. Discover how agentic produ...
Read more
The Present and Future of Software Development with AI
AI is reshaping software development - lowering barriers, speeding delivery, and intensify...
Read more
Launch Your First Secure SaaS API in 5 Days
Looking to launch a secure SaaS API quickly? Our 5-day API lifecycle fast-track helps star...
Read more
Cloud Cost Optimization: Quick Wins to Slash Unnecessary Spending
Discover quick wins for cloud cost optimization! Learn how to cut unnecessary spending, ri...
Read more
